

이 논문은 StyleGAN2보다 좋은 품질을 얻는 것이 아니라, 경량화와 MLP의 특성을 갖는 모델을 만드는 것을 목표로 두고 있다.
이를 위해 FMM과 Multi-Scale INR을 제안하였다.
FMM은 Style Code를 분해하여 곱연산하는 것이고 Multi-Scale INR은 Synthesis Network의 매 블럭마다 촘촘해지는 좌표 그리드를 입력하는 것이다.
같은 시기의 CIPS와 비교하였을 때 성능은 떨어진다.
Paper: https://arxiv.org/abs/2011.12026
Github: https://github.com/universome/inr-gan
Introduction
INR-GAN의 INR은 Implicit Neural Representation이며 이미지를 2D array로 다루는 것이 아니라 좌표값에 따른 각각의 픽셀을 다루는 방식을 의미한다.
이 논문은 INR에 있어서 Factorized Multiplicative Modulation(FMM)과 Multi-Scale INR을 제안하며 이를 통해 당시 Continuous 이미지 생성 분야에서 SoTA를 달성하였다.
또 이미지 외부를 SR 한다거나 이미지 공간상의 Interpolation, 외부에서의 extrapolate, 강력한 geometric prior 등 다양한 특성을 보여준다.
이전에 리뷰하였던 CIPS는 같은 시기에 나온 논문으로 CIPS가 더 좋은 성능을 보여주지만 위의 다양한 특성들에 대한 시도는 없었다.
Factorized Multiplicative Modulation (FMM)

StyleGAN2는 mapping network와 synthesis network로 나뉘어있는 hypernetwork이다. 그런데 이 모두를 계산하는 과정은 아무리 작은 hidden size를 갖도록 한다고 해도 계산 비용이 클 수밖에 없다.
그래서 저자는 Figure 6 (a)에서 볼 수 있듯이 weight $W$를 $W_s\odot\sigma(A \times B)$로 factorize하여 계산 비용을 줄인 것을 볼 수 있다.
이렇게 분해한 방식이 저자가 제안한 FMM으로 행렬 $W=A \times B$로 분해하는 것과는 약간 다르다.
만약 그냥 행렬을 분해하여 그 행이나 열이 줄어드는 경우(rank의 감소) 분해한 행렬의 특이값(Singular values, wikipedia)이 0이 되는 경우가 많다는 문제를 가지며, 이는 GAN 학습을 불안정하게 만든다.
이 문제를 방지하기 위해서 hypernetwork의 출력은 여전히 factorize 되어 있지만 행렬의 rank가 감소하지 않도록 parametrization 방식을 바꿨다.
$l$번째 레이어의 weight $W^l$에 대해서 각 레이어가 기본적으로 갖는 $W_s^l$을 정의하고 modulate에 사용되는 행렬 $W_h^l$을 $A^l \times B^l$로 분해하였고 이것에 활성화 함수를 적용하였다.
그래서 각 레이어에서 입력에 곱해지는 weight $W_l$는 다음과 같은 수식에 의해 결정된다.
$$W_h^l=A^l \times B^l$$
$$\begin{align}W^l &= W_s^l\odot\sigma(W_h^l)\\ &= W_s^l\odot\sigma(A^l \times B^l)\end{align}$$
그러면 StyleGAN2의 ModConv와 비교하면 어떤게 바뀌었을까?
INR-GAN에서 modulate에 사용되는 행렬이라 함은 Style Code인데 StyleGAN에서는 Convolution weight에 활성화 함수나 분해 없이 style code를 곱해주었다.
INR-GAN에서 사용한 변수를 사용해서 StyleGAN2의 수식을 나타내면 다음과 같다.
$$W^l=W_s^l \odot W_h^l$$
그러므로 FMM은 Style Code만 low rank로 분해한 후 활성화함수를 취한 것이다.
W와 Style Code의 곱을 W와 A와 B의 곱으로 분해한 것으로 개인적으로 이게 novelty가 있는지는 모르겠다.
이런 것은 Spatial/Depth Decomposed Convolution과 같이 적용만 하면 되는 것으로 매우 단순하기 때문이다.
Multi-Scale INR

INR Decoder를 고해상도로 scaling하는 것은 각각의 픽셀을 연산해야 하기 때문에 정말 연산량이 많다.
만약 1024 해상도의 이미지를 만든다면 Synthesis Network에 1,048,576개의 좌표를 입력해야 한다.
104만 개의 batch를 입력하려면 하드웨어 자원이 매우 많이 필요하다.
이를 위해 제안한 것이 Multi-Scale INR이며 Synthesis Network를 K개의 블록으로 나누어 각 블록은 각자만의 해상도 하에서 동작하도록 하였고 마지막 레이어만 목표 해상도에 맞게 동작하도록 하였다.
저층의 블럭은 저해상도 좌표 grid를 받아 feature를 연산하여 다음 블록으로 전달하며 점점 고해상도 좌표 grid를 통해 해상도를 높인다. 이는 처음부터 고해상도를 연산하는 것보다 연산량이 훨씬 적다.
이런 방식은 일반적인 Decoder의 Convolution Layer에서 점차 해상도를 높여간다는 점에서 유사하다.
각 블럭은 2개에서 4개의 레이어를 가지며 첫 블록은 64 해상도를 갖고 그 출력을 Nearest Neighbor Upsampling 하여 128 해상도로 만들어 다음 블록의 입력으로 사용한다.
이렇게 블럭마다 해상도를 다르게 만드는 것은 CIPS와 비교하였을 때 어떤 차이점이 있는가?
CIPS는 처음부터 고해상도 좌표를 입력하여 모든 픽셀을 독립적으로 연산한다.
그러면 INR-GAN은 각 픽셀을 독립적으로 연산할 수 있는가? 하나의 픽셀만 연산할 수 있는가?
그럴 수 없다는 점에서 차이점이 있다.
INR-GAN의 픽셀은 목표 해상도 / 64 만큼의 픽셀들이 서로 종속적이다.
예를 들어, 1024 해상도를 목표한다면 16개의 픽셀이 서로 종속적이라는 사실을 알 수 있다.
이 방식이 novelty는 있지만 각각의 픽셀을 연산한다는 최초의 목적은 희석되었다고 생각된다.
Experiments
FID Score & Efficiency

Table 1을 보면 StyleGAN2에 비해 곱연산 횟수(MAC)가 매우 줄어든 것을 볼 수 있어 확실히 Multi-Scale INR이 연산에 도움을 주는 것을 알 수 있다.
이 논문이 StyleGAN2보다 좋은 품질을 얻자는 목표가 아니라, 경량화와 MLP의 특성을 갖는 모델을 만드는 것이 목표라는 점을 생각하면 Convolution 없이도 FID 6이라는 괜찮은 수치를 얻은 것을 보면 결과물이 꽤 괜찮다.
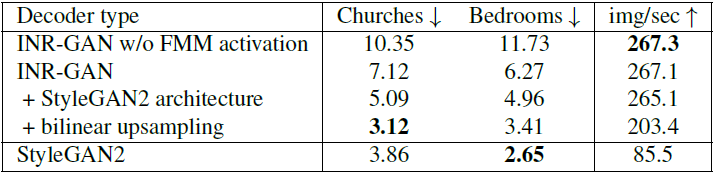
Table 1을 보면 StyleGAN2보다 Parameter 수는 117M으로 훨씬 많지만 Table 2를 보면 3배 빠르다는 것을 알 수 있다.
Parameter가 많은 것은 mapping network G의 출력이 아주 거대해서 그런 것으로 $10^3 \times 10^5$ 차원을 갖고 있고 전체의 90~99%의 Parameter를 갖고 있다. 이를 줄이는 것이 Future work라고 한다.
Ablating FMM rank

FMM 과정에서 A와 B의 rank를 몇으로 설정하는 것이 좋은가에 대한 실험이다.
Figure 6 (a)의 경우 A와 B를 rank 2로 분해하였다.
A와 B의 rank가 높을수록 FID는 낮을 것이고 계산 비용은 높아지는 것은 자명하며 저자는 rank 10으로 선택했다.
Extrapolating outside of image boundaries

Figure 10은 LSUN Bedroom 데이터로 학습한 INR-GAN에 좌표 Grid 범위를 초과하여 입력한 결과물이다.
[-0.5, 1.5]범위를 입력한 결과물인데 [-0.4, 1.4]를 넘어가는 순간 품질이 급격하게 떨어진다고 한다.
Interpolation

INR-GAN이 좀 더 합리적인 결과물으로 보이는데, 이는 (a)가 Latent Interpolation이 아닌 이미지 Interpolation이므로 자명한 결과다.
보통 GAN에서는 latent interpolation을 비교하는데, 이미지 Interpolation과 비교하는 것은 의미가 없다고 생각한다.
Keypoints prediction


Mapping Network의 입력인 Latent code Z와 Mapping Network의 출력인 Latent code W를 입력으로 사용하였을 때 Keypoints를 얼마나 잘 추정하는지에 대한 실험이다.
이 실험으로부터 Disentanglement를 대략적으로 실험할 수 있는 것 같은데 INR-GAN이 StyleGAN2보다 조금 더 Disentangle 되어있는 것 아닐까 싶다.
결론
- INR-GAN을 설계하기 위해 효율성을 높여주는 FMM과 Multi-Scale INR을 제안함
- StyleGAN2보다 3배 빠른 연산 속도를 가짐
- 다양한 실험으로 INR이 갖는 특성들을 보여줌
개인적인 생각
- 같은 Task를 다뤘던 CIPS에 비해 부족한 점이 느껴지는 논문이었음 (Oral과 아닌 것이 어디서 다른지 알 것 같음)
- 다른 것들은 좀 아쉬워도 Multi-Scale INR은 novelty가 확실한 것으로 보임
- Keypoints Prediction 실험이 꽤 흥미로웠음


댓글